

Stable distribution / OpenAI
On Tuesday, OpenAI announced a major update to its major language model API offerings (including GPT-4 and gpt-3.5-turbo), including a new ability to invoke functions, significant cost savings, and a context window option of 16,000 tokens for the gpt – 3.5 turbo model.
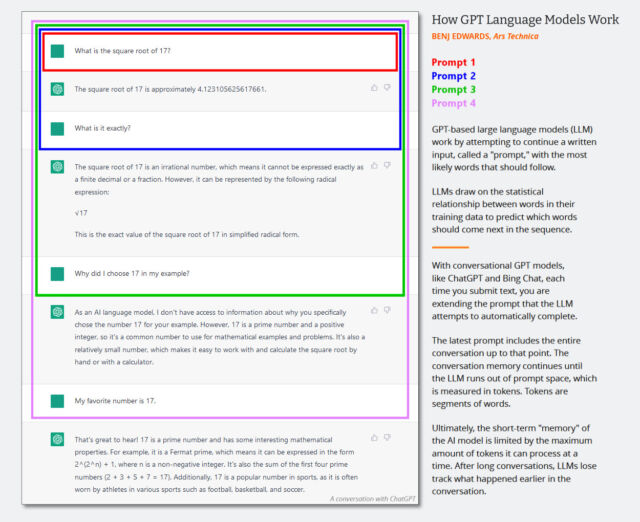
In large language models (LLMs), the “context window” is like a short-term memory that stores the contents of the prompt entry or, in the case of a chatbot, the entire contents of the ongoing conversation. In language models, increasing the context size has become a technological race, with Anthropic recently announcing a 75,000 token context window option for its Claude language model. In addition, OpenAI has developed a version of GPT-4 with 32,000 tokens, but it is not yet publicly available.
In that sense, OpenAI just introduced a new 16,000 context window version of gpt-3.5-turbo, unsurprisingly called “gpt-3.5-turbo-16k”, which allows a prompt to be up to 16,000 tokens long. With four times the context length of the standard version of 4,000, gpt-3.5-turbo-16k can handle about 20 pages of text in a single request. This is a significant boost for developers who need the model to process larger chunks of text and generate responses.
As detailed in the announcement post, OpenAI listed at least four other major new changes to its GPT APIs:
- Introducing function call function in the Chat Completions API
- Improved and “more drivable” versions of GPT-4 and gpt-3.5 turbo
- A 75 percent price reduction on the “ada” embedding model
- A 25 percent price cut on gpt-3.5 turbo input tokens.
Function calls now make it easier for developers to build chatbots that can call external tools, convert natural language into external API calls, or run database queries. For example, it can turn prompts like “Email Anya to see if she wants to get coffee next week” into a function call like “send_email(to: string, body: string).” Notably, this feature also enables consistent JSON-formatted output, which API users previously found difficult to generate.
With regard to “steerability,” which is a fancy term for the process of making the LLM behave the way you want it to, OpenAI says the new “gpt-3.5-turbo-0613” model “provides more reliable controllability via the system message ” will contain. .” The system message in the API is a special command prompt that tells the model how to behave, such as “You are Grimace. You only talk about milkshakes.”
In addition to the functional improvements, OpenAI offers substantial cost savings. In particular, the price of the popular gpt-3.5 turbo entry tokens has been reduced by 25 percent. This means that developers can now use this model for about $0.0015 per 1,000 input tokens and $0.002 per 1,000 output tokens, which equates to about 700 pages per dollar. The gpt-3.5-turbo-16k model costs $0.003 per 1,000 input tokens and $0.004 per 1,000 output tokens.
Benj Edwards / Ars Technica
Further, OpenAI offers a massive 75 percent cost reduction for its “text-embedding-ada-002” embedding model, which is more esoteric to use than its conversational brethren. An embedding model is like a translator for computers, converting words and concepts into a numerical language that machines can understand, which is important for tasks such as searching text and suggesting relevant content.
As OpenAI continues to update its models, the old ones won’t last forever. Today, the company also announced that it is beginning the write-off process for some earlier versions of these models, including gpt-3.5-turbo-0301 and gpt-4-0314. The company says developers can continue to use these models until September 13, after which the older models will no longer be accessible.
It’s worth noting that OpenAI’s GPT-4 API is still behind a waitlist, yet widely available.