
On Wednesday, Microsoft Introduced Research Magma, an integrated AI Foundation model that combines visual and language processing to control software interfaces and robot systems. If the results keep up with Microsoft's internal tests, this can mark a meaningful step forward for a multimodal AI with a complete goal that can work interactively in both real and digital spaces.
Microsoft claims that Magma is the first AI model that not only processes multimodal data (such as text, images and video), but can also act native to it – whether it navigates by a user interface or manipulating physical objects. The project is a collaboration between researchers from Microsoft, Kaist, the University of Maryland, the University of Wisconsin-Madison and the University of Washington.
We have seen other robotics projects based on large language model, such as Google's Palm-E and RT-2 or Chatgpt from Microsoft for robotics that use LLMS for an interface. In contrast to many previous multimodal AI systems that require individual models for perception and control, Magma integrates these skills into one foundation model.
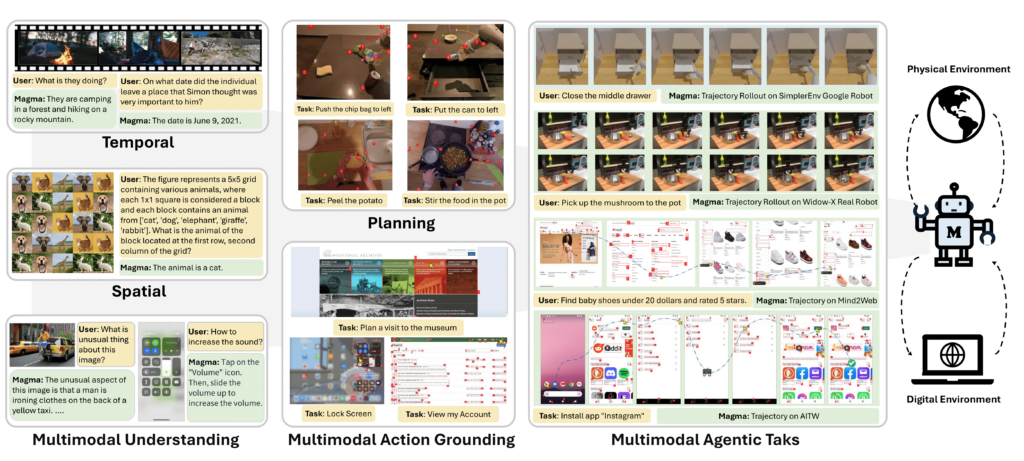
A combined image that shows with various options of the Magma model.
Credit: Microsoft Research
Microsoft positions Magma as a step in the direction of Agentic AI, which means that a system can make plans and perform Multistep tasks for a person instead of just answering questions about what it sees.
“Given a described goal,” writes Microsoft in his research paper. “Magma is able to formulate plans and implement actions to achieve this. By effectively transferring knowledge of freely available visual and language data, Bridges Magma verbal, spatial and temporary intelligence to navigate complex tasks and institutions.”
Microsoft is not only in the pursuit of agentic AI. OpenAi has experimented with AI agents through projects such as Operator who can perform UI tasks in a web browser, and Google has investigated several agent projects with Gemini 2.0.
Spatial intelligence
Although Magma builds on transformer-based LLM technology that feeds training to Tokens in a neural network, it differs from traditional vision language models (such as GPT-4V, for example) by going beyond what they call “verbal intelligence” to also record ” Spatial intelligence “(implementation of planning and action). By training on a mix of images, videos, robotics -data and onion interactions, Microsoft claims that Magma is a real multimodal agent instead of just a perceptual model.