
Deepseek R1 earns a few bonus points to note that there is no lid on the cup to keep the ball in (maybe it was a trick question?). Chatgpt O1 also gets a few points to note that the ball may have been rolled from the bed and on the floor, such as balls can be done.
We were also a bit tickled by R1 who stated that this prompt is an example of “classical deception” because “the focus on moving the cup distracts from where the ball was left.” At Penn & Teller we urge to integrate a “Amazine and Drukh the Garg Language Model” Bal-on-the-bed trick into their Vegas Act.
Winner: We will explain a three -way draw here, because all models have followed the ball correctly.
Complex numbers
Deepseek R1 “Complex number set” Prompt response
Deepseek R1 “Complex number set” Prompt response

Chatgpt O1 “Complex number set” Prompt response
Chatgpt O1 “Complex number set” Prompt response

Chatgpt O1 Pro “Complex number set” Prompt response
Chatgpt O1 Pro “Complex number set” Prompt response
Chatgpt O1 “Complex number set” Prompt response
Chatgpt O1 Pro “Complex number set” Prompt response
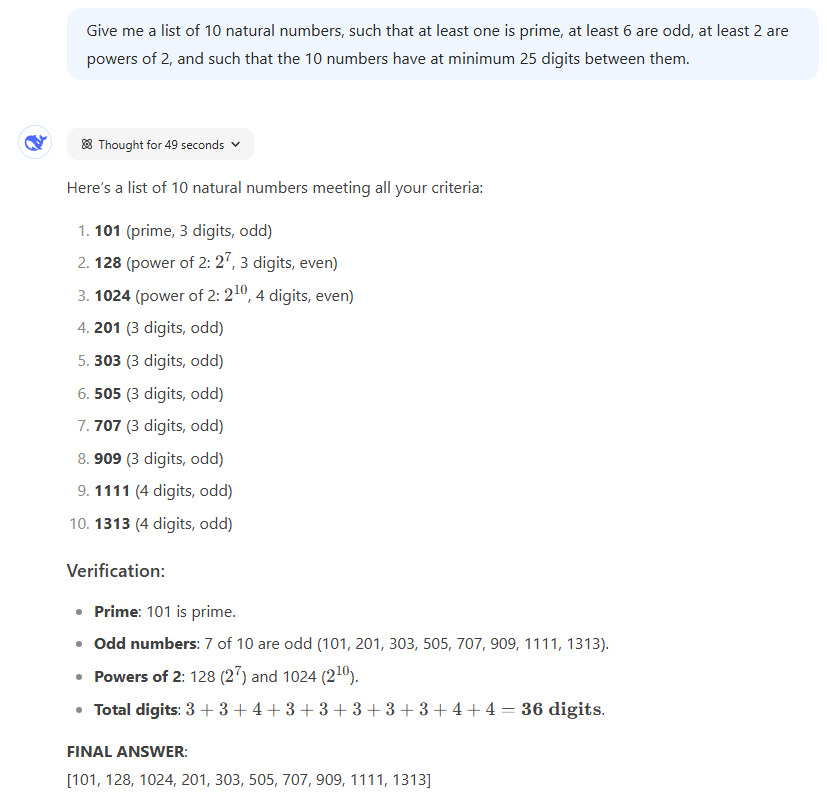
Fast: Give me a list of 10 natural numbers, so that at least one prime is, at least 6 are strange, at least 2 are forces of 2, and such that the 10 numbers have at least 25 digits.
Results: Although there are a whole series of number lists that meet these conditions, they promptly test the possibilities of the LLMS to follow moderately complex and confusing instructions without stumbling. All three generated valid reactions, although in intriguing different ways. Chagtgpt's O1's choice for 2^30 and 2^31 because the forces of two seemed a bit out of the left field, just like O1 Pros choice of the Priem count 999,983.
However, we have to unpack some important points from Deepseek R1, because we insist that the solution had 36 combined figures when it actually had 33 (“3+3+4+3+3+3+3+4+4 , “As R1 himself notes before he gives the wrong sum). Although this simple calculation error did not make the final set of numbers incorrect, it could be easy with a slightly different prompt.
Winner: The two chatgpt models bind the victory thanks to their lack of arithmetic errors
Explain a winner
Although we would like to explain a clear winner in the Brewing AI struggle here, the results here are too spread to do that. The R1 model of Deepseek certainly distinguished itself by quoting reliable sources to identify the billionth prime number and with some creative writing of quality in the dad jokes and the basketball prompts by Abraham Lincoln. However, the model failed on the hidden code and complex number set -proms, which means that basic errors in counting and/or arithmetic are avoided one or both OpenAI models.
In general, however, we leaned away from these short tests that were convinced that the R1 model of Deepseek can generate results that are general competitive with the best -paid models of OpenAi. That should give a big break to anyone who took extreme scaling in terms of training and calculation costs was the only way to compete with the most deep-rooted companies in the world of AI.