

There’s a buzz in the AI world about a new AI language model released by Meta on Tuesday: Llama 3.1 405B. The reason? It’s possibly the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop-PC-quality gear. But it’s a provocative shot across the bows of “closed” AI model vendors like OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the best AI models in terms of state-of-the-art capabilities in general knowledge, controllability, mathematics, tooling, and multilingual translation,” Meta said. The company’s CEO Mark Zuckerberg calls 405B “the first open source, frontier-level AI model.”
In the AI industry, a “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta 405B positions itself among the industry’s best AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
A graph from Meta shows that the 405B comes very close to the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks such as MMLU (undergraduate knowledge), GSM8K (elementary school mathematics), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound, and they don’t capture the subjective experience of interacting with AI language models. In fact, this traditional set of AI benchmarks is so generally useless to laypeople that even Meta’s PR department has only posted a few images of numerical plots without attempting to explain their meaning in detail.
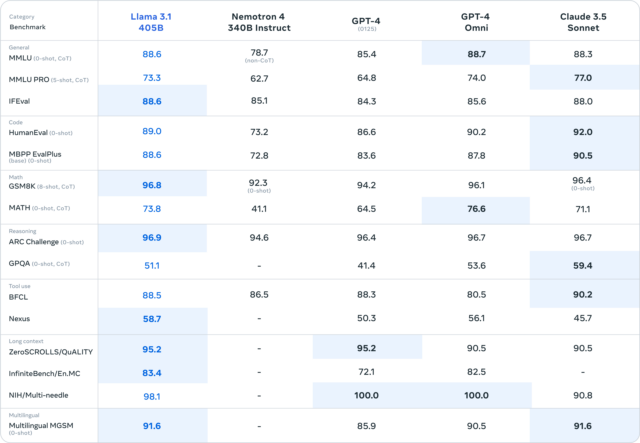
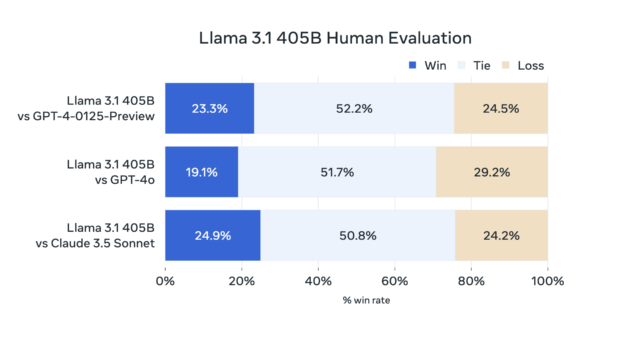
Instead, we’ve found that measuring the subjective experience of using a conversational AI model (through what you might call “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to evaluate new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs, which seem to show that Meta’s new model holds its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Whatever the benchmarks, the initial word on the street (after the model leaked on 4chan yesterday) seems to be that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there – and money, of which the social media giant has plenty to spare. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using over 16,000 H100 GPUs.
So what’s with the name 405B? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capabilities, such as a better ability to make contextual connections between concepts. But models with larger parameters come with a trade-off in the need for more computing power (aka “compute”) to run them.
We've been expecting the release of a Llama 3 family model with over 400 billion parameters since Meta announced back in April that it was training one. Today's announcement isn't just about the largest member of the Llama 3 family: there's a whole new version of enhanced Llama models dubbed “Llama 3.1.” That includes upgraded versions of the smaller 8B and 70B models, which now offer multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says 405B is useful for long-form text summaries, multilingual conversational agents and coding assistants, and for creating synthetic data used to train future AI language models. That last use case in particular, which allows developers to use outputs from Llama models to improve other AI models, is now officially supported for the first time under Meta’s Llama 3.1 license.
Misuse of the term “open source”
Llama 3.1 405B is an open-weights model, meaning anyone can download the trained neural network files and run or fine-tune them. This directly challenges a business model where companies like OpenAI keep the weights for themselves and instead monetize the model via subscription wrappers like ChatGPT or charge for access via the token via an API.
Combating the “closed” AI model is a big deal for Mark Zuckerberg, who today simultaneously published a 2,300-word manifesto on why the company believes in open releases of AI models, titled “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for adaptable AI models that offer user control and encourage better data security, greater cost efficiency, and greater future-proofing as opposed to vendor-locked solutions.
That all sounds reasonable, but disrupting your competitors with a model subsidized by a social media war chest is also an effective way to play spoilsport in a market where the most advanced technology doesn’t always win. Open releases of AI models benefit Meta, Zuckerberg says, because he doesn’t want to be locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very specific meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on a terminology for AI model releases that ship constrained code or weights (like Llama 3.1) or that ship without providing training data. We have instead called these releases “open weights.”
Unfortunately for terminology purists, Zuckerberg has now slipped the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the right term in AI may be a losing battle. Still, its use irritates people like independent AI researcher Simon Willison, who incidentally likes Zuckerberg’s essay.
“I see Zuck's prominent misuse of 'open source' as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed-upon meaning. Misuse of the term dilutes that meaning, making the term less generally useful, because when someone says 'it's open source,' that doesn't tell me anything useful anymore. I have to dig around and figure out what they're even talking about.”
The Llama 3.1 models are available for download from Meta's own website and from Hugging Face. Both require you to provide contact information and agree to a license and acceptable use policy, meaning that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.